赤石先生の行っている研究
以下では、「知識の液状化」と「知識の結晶化」について述べていきたいと思います。
まずは「知識の液状化」について。赤石先生は自然言語処理を用いて文章内の単語(特にこの場合は名詞)を抽出し、統計処理(条件付確率等の確率計算)に基づき、文章中において、同じ文に出る頻度が高い単語同士を線で結びつけることによって、単語間の関係を視覚化しました。文書から名詞のみを抽出する自然言語処理に関することはまた別の分野の話なので今回は省略します。
統計処理についてですが、語AとBがあったときに、AからBへの共起依存度とは、語Aが出現した時に語Bが出現する条件付確率と定義します。つまり、対象としている文書において、(AとBを同時に含む文の数)÷(Aを含む文の数)と書けます。そして語Aの吸引力を、上の式において語Bだけではなくて全ての名詞について上の確率を求めてそれらを全て足し合わせたものと定義します。
少々難しいかもしれませんので、具体的に桃太郎の話で考えてみましょう。「桃太郎」と「きび団子」は同じ文の中に一緒にでてくることが比較的多いですね。従って「桃太郎」と「きび団子」は共起依存性が高いと言えます。しかし、「おばあさん」と「鬼」は同じ文の中に一緒にでてくることは少ないですね。従って「おばあさん」と「鬼」は共起依存性が低いと言えます。そして、桃太郎の話に出てくる全ての単語同士で考えた場合、「桃太郎」はいろいろな単語と共起依存性が高いことがわかります。従って、「桃太郎」は吸引力が高いと言うことができます。
このように語と語の出現頻度の関係でグラフにしてみると、文書において重要な語だけが抽出されてくもの巣のように(写真1参照)視覚化されます。写真1は実際に私達のサイトに掲載されている、立花さんの挨拶文をこの方法で視覚化したものです。写真のように、メディアとサイエンスという言葉の吸引力が大きく、この文書を読まないでも、この視覚化されたグラフを見るだけでおおまかな内容をとらえることができます。
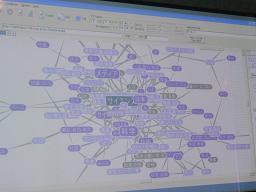
(写真1)
さらに意味段落で区切り、その段落ごとにグラフをつくると、自分の興味のあるところだけ取り出して読むこともできます。テキストを視覚化したグラフをいろいろ操作することで、文書の書かれた順番を保ちながら分解したり、順番は変更されるけれど関連するところだけをつなぎ合わせて分解したりできるのです。
これまでは「知識の液状化」についての説明を行ってきましたが、次は「知識の結晶化」についての説明をします。これは自分が調べたい言葉を含んでいる文だけを取り出して、それを視覚化することによって、その言葉がどのような主題を持っているかを知ることができるのです。(写真2参照)
(写真2)
今回私が研究所をお邪魔したときにはギリシャ神話について調べてみてもらいました。例えば「愛」という言葉を調べてみると、ギリシャ神話における愛のドキュメントのマップが得られます。このマップは、ただ単に愛という語を含んだ文のリストではなくて、ゼウス関係の内容が述べられている文はこのあたりにあるとか、芸術と愛の神様がいるだとか、ポセイドンはゼウスの兄弟だとかいうことがわかるのです。これを用いることによって、自分が思いつかなかったようなギリシャ神話の筋が見えてきます。
さらにこのギリシャ神話の場合、人間と神についての関係を調べるなら、グラフに現れている人間という語と神という語をくっつけて、そこからでてきた語をたどることで、女神官は結婚が許されていない・・・などということまでもわかります(写真3)。また、文章全体から「ゼウス」という単語を除いて各々の語の共起依存度を再び調べるといった切り方でみると、祭りに関する事柄もわかってきます。つまり、切り方を変えて調べると違う情報が得られるのです。
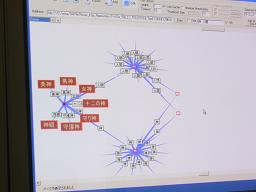
(写真3)
文責:永田 育真

準備中