1塩基の違いが疾患の引き金
| 林崎 | ああそうですか。いやびっくりするような話がまだあんねん。
SNP(一塩基多型)って知ってる? あの、アルデヒド脱水素酵素というのは、エタノール、ようするにお酒を分解するために必要で、大学入って一気飲みさせられてして死んだ人がいたでしょう、あれはアセトアルデヒドを代謝できない人なんですよ。できるんやけど、代謝する酵素の活性が弱い。エタノールはアセトアルデヒドになって、酸化つまり脱水素されて酢酸になって、それがアセチルCoAに入ってTCAサイクルを回る。エタノールがたまっているうちは気持ちよくていいんだけど、アセトアルデヒドはすごく気持ち悪いんよ。で、アルデヒド脱水素酵素の活性が弱いというのは、それをコードしている遺伝子のある部分が変異しているんですね(遺伝子の配列が二つ表示される。スライド21) これ、両方ともアルデヒド脱水素酵素の遺伝暗号なんですけど、一個(塩基が)違うだけど、ぱっと見てわかる? |
| 学生B | あ、あった。上から3行目の真ん中の… |
| 林崎 | すごい!(答え) あなた、4人目ですよ、ぱっと答えたの。スーパーインポーズして見る技術を持っている人が二人いた。あとは、そこに記事があるけれど、7月20日、ついこの前スーパーサイエンスハイスクールで実習をやってきて、そこでこのアルデヒド脱水素酵素の話をしたら、わかった生徒がいた。この一塩基が違うと、酵素の中でグルタミン酸がリジンになってしまって、代謝活性が弱くなるわけ。この遺伝子が、お父ちゃんからもらったのと、お母ちゃんからもらったのとどっちも弱い方な人は、これは本当に弱い人や、人口の約4パーセントぐらいいる。それから46パーセントくらいがヘテロ。残りが野生型のホモで、まあまあ飲める人。 っていう、例えばこういうような、人による一塩基の違いっていうのは、人の30億塩基の配列のうち、1100万くらいあると。つまり、人の固体間では、300個に一個くらいの塩基の違いがある。まぁ日本人同士だと1000個に1個くらい。でも、人とチンパンジーの間には、100個に1個か2個だから、人同士の違いは、人とチンパンジーの違いの三分の一しかないという、ショックな。(スライド22) この、一塩基多型っていうのは、薬の効き方とか、花粉症とか、癌とか、成人病とかのなりやすさ、癌の場合は転移するかしないかとかいうことに関わってくる。 例えば胃潰瘍に対して、特定の変異を持っている人には、薬を三倍量で与えなきゃいけなかったりする。 他にも、いろいろなことがSNPで決まっている。びっくり遺伝子とか。冒険好きとかギャンブル好きまで(笑)、どの遺伝子のどこに変異があるとどういう性格になるかっていうのが、わかってきつつあるわけですよね。(スライド23)冗談じゃなくてあるわけですよ。もちろん、性格のように複雑な要素は一つの遺伝子で決まるものではありません、と注釈をつけてますけどね。でも、個人の一塩基の変異を見ていくのが重要だというのは、わかりますでしょう。 |
加速するシークエンシング技術
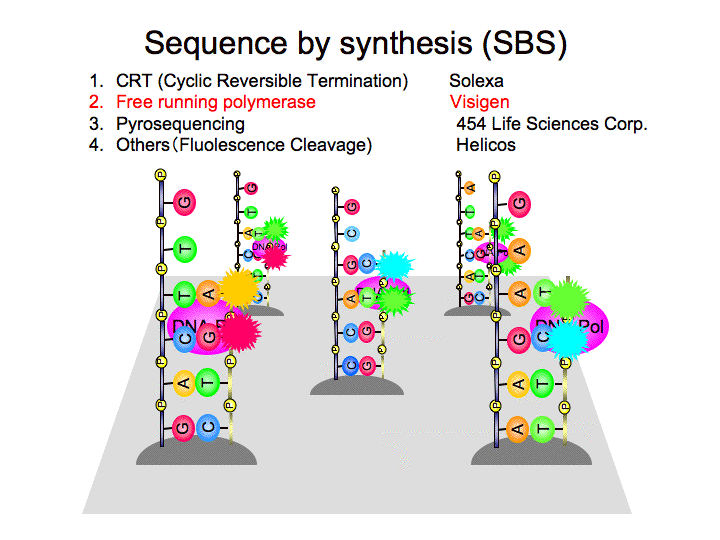
| 林崎 | で、ここからがすごい。さっき、シークエンスを一日に4万個やる、っていいましたよね。そんなレベルでがんばって、インフルエンザウィルスのゲノムを解読したのが95年なんですね。そこからどんどん進んで、ショウジョウバエ、マウス、ヒト、イネ、カ、ラットまで、どんどん登録数が増えてきているわけですよね。そうすると、2009年までに、2000個体の遺伝子が決まると。これはよう考えるとすごいことやで、だってヒトは1個体ですからね。あなただったら、どんなゲノムの配列を決めます? と聞かれたら、ヒトの次は、牛とか豚とか、もうやっていますけど、小麦とか、にんじん、キャベツ、かぼちゃ、きゅうり、レタス、キャベツとか。でも1500個の生物挙げろ、って言われたら、無理でしょ。要するに、2009年にはシークエンスするべきゲノムがなくなるんです。だから、君らが卒業するころには、ゲノムプロジェクトなんてナンセンス。そんなのデータベースみたらいいじゃないってことになる。 1990年、私がワトソンさんに電話した年ですね。世界中の機械を使ってヒトの全ゲノムのシークエンシングに4000年かかるって。1993年には、400年かかるわって言っていたわけですよ。それでは終わらないな、なんて言っていたときにはまだ高をくくっていたわけだけど、次、僕が着任した年ね、1995年になると、4000億円かけて、2003年までにやっちゃうぞと。2003年には、40億円かけて、大規模なセンターの機械を使ったら、1ヶ月でできちゃうよと。よく考えたら、私のグループのパイプラインを使って、40億円突っ込んでくれたら、できていたんですけどね。ところが、2010年には、このくらいの大きさの機械を一つ買って、学生さん一人働いたら、一日で、数時間で、10万円で、ヒトゲノム全長が決まる機械ができると。 これ、シークエンサー一台で解読可能なDNAの塩基数のグラフなんですけど、2006年つまり今年はもう、かけないんですよ。(スライド24)天井突き抜けちゃう。5時間で2千万塩基ですよ。1ベースを解読するためのコストも、こういう風に対数グラフでどんどん落ちてきている。何がいいたいかだんだんわかってきました? これ、アメリカの$1000ゲノムプロジェクトというのは、十万円あれば、5時間で、機械を動かせばヒトゲノムのシークエンシングができますよと。DNAを小さい断片にちょんと切って、一個の液滴の中に一つのDNA分子が入るようにする。それぞれの液滴の中でPCRをして、そのDNA分子を液滴の中に複製しておくわけ。これを、こういうとても小さい孔の中に一滴ずつ入れて、それをシークエンシングするんですよ。上からだっと液を流すと、孔からそれぞれ光がでてくるからそれを読むという、バイオシークエンスという方法なんですけど。一個の穴から100個の塩基が出てきて、20万個の孔があるから、一気に2000万塩基が一気に決まると。それは20メガでしょ。大腸菌だと4メガぐらい。結核菌なんて培養に2週間かかるとかいうんですけど、そんなことしている間にシークエンシングするほうが早いって言う、そういう時代がきているわけです。あとはコストの問題だけです。僕らが今まで建設してきた、一日4万個の機械なんて、いまや戦艦大和みたいなもんですよ。一台で2000万塩基一気に決まるやつが理研に一号機、って記事が出ていますけど、こんなもん世界中でどんどん売れているわけですよ。でもこれでびっくりしていたらダメなんですよ。 今度はどんなやつが出てきたかというと、チップの上にDNAをびゃっと撒いて、その中でDNAをポリメラーゼ使って合成させていくと。そしたら、最初に蒔いた、元の鋳型になるDNAに対して、相補的な塩基が一塩基ずつ引っ付くたびに、その新しい塩基とポリメラーゼの相互作用でピカァって光がでるわけ。そして、その光の色が、取り込まれた塩基ATCGのそれぞれで違うから、上からCCDカメラでどんな順番で光ったかをざーって見ていけば、配列がわかるっていう。(スライド25)これは、来年の今日にはうちでも動いていますよ。これだとね、数時間で10億塩基。ヒトゲノムの3分の1で三時間もあればシークエンスできるようになる。 そんなのでびっくりしていてもダメなんです。というのは一分子でDNAのシークエンシングでてきましてですね、2010年に完成する予定なですけど、これは現在あるんですよ、売ってないだけで。来年商業化されます。(スライド26)これは今開発中なんですが一分子シークエンシングていうものがありましてね、実は合成したときに光るのはやるんだけどこれにはアイデアがあるんだよ。ポリメラーゼにフルオラローブ、蛍光色素をついてるわけ。これ取り込んだとき、Aに対してはTを取り込みますね。Tのリン酸が三つついている、そのγ位のリン酸にTにspecificな別のフルオロフォアがついています。AにはA-specific、GにはG-specific、CにはC-specificなフルオロフォアがついているんですよ。一旦、(デオキシリボ核酸を)取り込んだ瞬間にレーザーを当てているわけです。そうするとこのフルオロフォアから、見えた? エナジートランスやったんだけど、ピカッと光るわけ。これ(DNAポリメラーゼ)を励起して、蛍光がこれ(DNA)を励起してこの蛍光色素を見る分けです。。それで次にいくとまた別の光が見えるわけ。AならAを、GならGを。これを上からざーっとみるわけですね。これによって1ミリ秒間に960塩基よむんですよね。一秒間に100M塩基読みます。そうなると十時間で300億塩基読みます。さっきの30倍ですよね。そうなるとヒトゲノムの10倍量読むわけですね。ヒトゲノムの一カ所を10回読むわけですからつながるんですね。で、ゲノム全長が決まってしまう。 そうなるとどんな話になるかっていうと、もう一つ技術があって、これだけで驚いちゃいけないんだけど、ナノポア(スライド27)っていうのがあってこれ今開発中なんだけどビックリするでー。これはシリコンウエハのナノの穴をあける。ナノってわかる?DNAの一分子だけ通るような穴をあけるわけ。針に糸を通すみたいに。 DNAをいれておいて上から電気をあてるわけ、そうするとシュルシュルシュルって通る。そのシュルシュルって通るときに、GACTって通るときにここでトンネル電流を測るわけ。トンネル電流を測るとAとGとTとCで違うわけ。AとCはちょっと違うけどそれを覚えるわけ。で、これ予測なんだけど、まだ開発中だから。電気の消費速度の方がLimitationなわけ。一秒間に理論上に10の9乗の塩基読めちゃうわけ。一秒間に10の9乗の塩基読めちゃうのはちょっとどうかな、と思うでしょう。だから話半分に考えて、10分の1、つまり10の8乗の塩基を1秒間に読めると考えても10秒間でヒトゲノムが読めちゃうわけよ。だから外来に行ったときにテストテープいって尿検査受けてあなたの全ゲノム配列がわかりますよ、ってことになるよね。ちょっとあぜんとするでしょ。 そうするとね、どうなるか?というとね。こうなるんじゃないかと思うよ、パーソナライズド・プロジェクトというのがあります。ヒトのゲノムって一生変わらないじゃん。産まれたときに一回はかればいいわけでしょ。ほら、さっき新生児のスクリーニングの話をしたでしょ、(脳)下垂体のクレチン症みるって言ったでしょ。そんなやるなら全ゲノム配列わかったほうがいいじゃん。女性がね、今出産するでしょ、その女性にね、出産一時見舞金を10万円だすことにする、地方交付公共団体がだしている。それでこれがね、出産見舞金の申請書なんやけど、あなたは新生児の全ゲノム配列が欲しいですか?現金10万円が欲しいですか?マルしなさいっていうのが例えばあって、こういう時代がくるだろうと。で、日本国の中で年間産まれる新生児の全員のゲノム配列を測るとすると、千ドルゲノムプロジェクトが実現するといくらかかるかというとわずか1358億円なんですよ。で、今保険の費用って30兆円ぐらいですよね。安いじゃないですか。それに予防医学的には完璧。あなたは何歳ぐらいで結腸ガンになりますから注意してください。そういう時代がくるわけですよ。えーって感じですよね。でも大問題があるんですよ。あなたのDNA、あなたのDNAが10万で終わっちゃうわけですよ。全長の配列がわかるわけ。そうなると、そんなもん保険会社に使われるとどうなっちゃうの?えらいことになるよね。それから自分、治らない病気なんて知りたくないようね。そんなん、無理矢理やられて教えられて。知らないでいる権利ってあるよね、絶対。差別なったりするよね。ゲノムシークエンスは個人に帰属するわけですよ。けど、個人の情報を勝手に抽出して個人の利益にならないようなことに使われたらどうなっちゃうのって、えらいことになるよね。ものすごく慎重にならなくてはいけない。 でね、これ一万サンプルから10万サンプル、こっち1000ザイ。1000ザイってわかるとおもうけど、いまこういう何とか法とかいっぱいあるんですよ、SNPを測る方法にしても。これはちょっと前をみれば、全部、$1000ゲノムプロジェクトに、だって全長のシークエンス以上のSNPゲノムはないじゃない、それで全部なんやから。これで十分やから。十二分だから。それでもこれはまずいのではないかと。腹立つのが全部アメリカの技術なので、日本の外貨は全部アメリカに吸い取いあげられるような話になってこれはいかんなーと。アメリカがゲノムやるって言ったときは僕はcDNAをやった、アメリカが$1000ゲノム計画をやるときは僕は違う方向に行くわけです。どっちに行ったかというと、1サンプルでいいからザイが1個以上、10個以上でも何個でもいいから限られた数をやる。ただし速い。というのは今、千ドルゲノム計画は全長見るから3かける10の9乗ザイ見ているわけね、だからアメリカはこっちの方向に進んでいるわけね。でも僕らはこっちの方向に進んでいる、数は変わらないけど速い方向へ進んでいる。速いと何ができるかっていうとね、例えば外来で患者さんが来てテステープみたいに待っている間にやってお医者さんの前にすわったときに(提出して)、ほらさっきの胃潰瘍の薬でもあったように、その人に合った薬を帰られる前までに処方できる。オペ中にガンを摘出するよね、例えばこのリンパ節に何個のガン細胞があるか、とかが分かったり、このガン細胞はイレッサによく効くとか。あるでしょ、(イレッサという)肺ガンの薬が。 |
SNP=個人情報
| 林崎 | こんなところかな。質問あります? |
| 立花 | 最初にワトソンに電話してこっちにはこういう技術があるって、数ケタ違う速さの技術があるって言いましたよね。それは電気泳動なんですか?二次元電気泳動なんですか? |
| 林崎 | それはロング法といいます。電気泳動とはこれはまったく違う、シークエンシング技術がまったくちがう技術です。DNAは今やシークエンシングする時代ですけど、昔はマッピングというのをやっていました。マッピングというのは地図づくりでDNAの中である鎖が必要だとそのときに30億もある中のここだけからシグナルがspecificにでる方法で、そのspecificにでる目印みたいのをランドマークといって、DNAマーカーなんですけどそのランドマークをどういうランドマークを置くかって話なんですけど。昔、サザン法というのがあったのを知りません? |
| 学生A | サザンブロッティングですね。 |
| 林崎 | サザンブロッティングというのはプローブがあって制限酵素で切って流してトランスファーしてハイブリッドさせてバンドが見える。あのバンド見えるという事がシグナルなわけですよ、DNAの特異的なシグナル。それでそこの部分を検出してわけですよ、視覚化していました。DNAがマーカーだった。その次の出てきたのがPCRです。PCRはプライマーをはさんで増えるやつですが、増えた事をシグナルだった。それを次のマーカーとして使い始めた。で、僕が発明したのが第3のマーカーだったんですよ。制限酵素っていう酵素がありますよね?制限酵素自体はノーベル賞をもらっているんですけど、制限酵素で切ったサイトそのものを視覚化しようと、ゲノムの配列から直接。例えば、EcoR1という6塩基を認識する酵素を使うと、大体30万個ぐらいの断片ができるんですね、ゲノム全体から。そうすると分離できないんですよ。だから長い断片、つまりレアに認識する酵素を使うわけですね、Not1というのを使います、8塩基カッターの。それで切って視覚化しようと思うのですが、今度は長いんですね、最初1G塩基あるから、分離できない。それでNot1で一度切って、末端をラベル化してもう一回6ベースカッターで切ってこう二次元にこうしてこうしてやると、ブアーってスポットがでる、3000個ぐらいいっぺんに。3000個のスポットの一個一個がPCRの一個に相当していて、だからPCRを3000回繰り返した情報量に相当するのでものすごく速いんですよ。当時は結構受けたんですけど。これ使って遺伝子クローニングをいっぱいやりました。けどその後、心筋症の遺伝子とかクローニングして論文書きましたけど。けども全部の遺伝子クローンしたほうが速いからっということで、こっちのほう(マウス完全長cDNA)をわざとやったわけです。そういう人生です。RNAiていうのが一方でがーって98年に出始めて、ファイアーとクリーブメローのグループで。で、僕らがこっちから来たのがnon-coding RNAが山のように出てきてncRNAがいろいろな機能をするわけです。そういうものが一緒になってRNAはすごいという話です。もはや、昔はこういうような着任したてのころの機械ってというのはもう古くて、今のシークエンシング技術とかDNA配列解析技術とかどんどん半導体工学のあとを追っていて全部のシリコンウエハの上で処理しています。それらを使うのと同時に我々も技術を開発していかなければならない、このSMAP(注1)とかみたいにね。これはあのSMAP(注1)のモップなんですけど、ここにサンプルをいれてしゅーと電気泳動で流れて測定する機械なんですけど、これより不細工な機械が今年の十二月ごろにでます。これそのものが来年の十二月ごろに市販になります。携帯電話のはその次かな。 |
| 学生C | これだけ早くシークエンスができるようになるとほかにもいろいろ問題があるんじゃないですか? |
| 林崎 | その通りだと思います。インフォームドコンセントとかね。 |
| 学生C | これも個人情報ですからね。 |
| 林崎 | だからいまの SMAP(注1)の方法で実は診断できるのです。でここの高校(SSHで)いってあなたあなたの遺伝子を、まあ酒酔い遺伝子だからそのぐらいいいだろうと思ってもそれはだめ、インフォームドコンセントを取っていてもだめ。で、自分たちのスタッフだったらいいだろうと思うけどこれもだめ。例えばそこの彼(理研の人)にちょっと血を頂戴、って言って彼がOKと言っても、この関係は上司が部下に対して血をだしなさい、ということになってパワハラ(パワーハラスメント)になるんですよ。職権と使ってそういう事を強要したことに受け取られるからだめなんですよ。だから結局どうしたかっていうと、ここに書いてあるんだけど、私自身が私自身の血をとって私自身のタイプを生徒の前で言います、それだったらいいんですよ。私が管理者だから自分の遺伝子は別に構わない。 |
| (同席していた)広報の方 | 立花先生が賛同して提供したらだめなんですか? |
| 林崎 | いや、立花先生の場合もインフォームドコンセントがいります。例えばみんなが酒酔い遺伝子の情報を知ってしまうわけですから。これも個人情報ですのでものすごいナーバスですよ。 |
| 立花 | そこの状況が将来変わる事はないですか。あまりにもありふれたものになったらどうでもいいってことになりませんか? |
| 林崎 | それはね・・・。じゃ、先生に最近聞いた話をしましょうか。酒酔い遺伝子だったらいいんじゃないか?と思うでしょ。酒酔い遺伝子のアセトアルデヒド脱水酵素に関して新たな知見が出てきまして、食道ガンの感受性遺伝子であると。それが弱い遺伝子の場合、食道ガンになりやすいわけですよ。なぜかというと、肝臓で摂取されますよね、アルコールは。そうするとエタノールがアセトアルデヒドになった場合、例えば肝硬変になった場合ね、冠静脈から大静脈へ還流していく血液は肝臓が固くなってしまうと戻らなくなってしまうわけね。詰まるわけですよ。で、どこから来た血液かっていうと食道静脈流を入ってきて、大吐血する可能性があります。肝臓が固くなってしまって血液の逃げ道がなくなると違うルートから大静脈に帰ろうとします。例えば、食道があったら皮下静脈というのがあってそこを通って大静脈に帰るルートがあって、そうすると時々圧力が高くなってどかーんって破裂してすごく吐血します。そうして出血死するケースが肝硬変にあります。かなり頻度が高いです。今はどうなったか知りませんが三分の一ぐらいだったと思います。僕がまだ医者をやっていたころはそのようなものを診ていましたけど。で、そうすると肝臓の中で、今言いたいことは食道が副側経路だということ。代謝の効率が悪いというのはアセトアルデヒドはなかなか分解されないから全体に流れていくわけですよ。特に食道に流れていくとアルデヒドという陰原因が食道にさらされる可能性が高くなるわけです。そうなると食道ガンになる、というのが理屈です。本当かどうかはまだ統計的にしか分かっていないのですが。もしそれが本当に裏付けられてきたら酒酔い遺伝子でも笑えなくなってくるわけですよね。それで個人情報が一度流れてしまった場合、大変なことになりますよね。SNPの意味合いが時間時間によって変わってくるから注意しないといけない。だから自分の情報を流していいですよという場合、場所を限定していてもですね、そのSNPの意味合いが変化する可能性を含めてアクセプトしないといけない。 |
| 学生A | 一つ質問よろしいですか?私たちの企画の中で様々な生命科学の研究者に質問を投げかけてその反応をみたら面白いんじゃないかって考えているのですが、質問自体はまだ決まってないのですが、non-coding RNAの研究によってセントラルドグマは生命現象のほんの一部という感じがしませんか? |
| 林崎 | セントラルドグマは生きているは生きているんですよ。さっきの図の通りですね、これね。これは正しいですよ。これはセントラルドグマの一部ですから正しいですよ。必ずしもこうなってこうなってタンパクになるかっていうとこれはマイナーであると、数からしたら。 |
| 学生A | non-coding RNAが関わってくるいろいろなメカニズムが分かってくると思います。その中で生命観ってものが変わってくるのではないかと、先生はどのように変わると思いますか? |
| 林崎 | 生命観ってのは何?生命観はどういうものを生命観と呼んでいるかにもよるよね。だからセントラルドグマみたいな公式があるんですが、公式通りじゃない部分もある。生物っていうのは何でもありという感じがするな。出来る事はすべて出来ているよね。一つの公式であてはめて言うのは、確かに化学物質としては公式・公理がありますが、それらがどういう反応をするかというレベルになるとありとあらゆる反応をしますよね。 |
| 立花 | なんでもしてきた歴史がnon-coding RNAの世界に刻印を残してそれが現に実は働いているわけですね。しかし、これは生命科学の大転換ですよね。 |
| 林崎 | ゴールドラッシュみたいですね。何かわからないけど誰かが旗を立てればその人が手にいれられますから。 |
| 立花 | 大変化が起こっていることを一般の人は知らないでしょ? |
| 林崎 | 知らないですね。言っているのですけど。きっかけは二つなんでよ、RNAiが98年に出て、そしてnon-coding RNAというのが出て開けてきた。 |
| 立花 | 昔は生命の起源の関係でRNA worldっていう言葉が使われましたよね。その時はファンクショナルにあたる部分はついてなくてただRNAがあるというだけだったのですか? |
| 林崎 | そうです。単にevolutionaryに生命の起源的な意味合いがあっただけです。 |
| 立花 | 今、それは区別するためにあっちはevolutionaryだというのはあるのですか? |
| 林崎 | 区別していませんね。 |
注1: SMAPとはSmart Application Processの略称で林崎先生が開発しているSNPを特異的に検知する方法です。取材当時は論文で公表されてなかったのでオフレコになりました。
不可欠な計算機の力
| 立花 | さっきおしゃっていた、コンピュータの計算力が生命科学の研究をするのに大変だという話をしていて、今、次世代スパコンっていうのをやっていますよね。あの中で将来的な使用目的にこの分野(ゲノム科学)が含まれていますよね。と言いますのは実は僕は次世代スパコンのアドバイザリーグループみたいなところに入っていまして中身をどうするかみたいな議論をしています。こっち側からどういうスペックが欲しいかという希望がだされていますか? |
| 林崎 | それは理化学研究所の中で理研の意見をまとめる委員会の中では僕は意見を言っているんですけれども、国全体から見ると理研は姫野さんだけが呼ばれていますが... |
| 立花 | もう少しいるんじゃないですか?たしかに姫野さんは中心ですがあと何人がいたような。 |
| 林崎 | いるんですけど一応、姫野さんがまとめ役なんです。姫野さんはライフサイエンスの出身ではないのですがニーズは圧倒的に僕らからのほうが多いですね。例えば、タンパクの分子動力学はうちの泰地くんというのがGRAPE-2という専用計算機を作っていて、今ので十分とは言いませんが結構、十分なんですよ。ところがこれはまったく新しい種類の分野で要求される計算の種類数が全然違う、データの量の超爆発が起きているんですよ。先ほどの場合でも一台のシークエンサーによるデータ量もものすごいし、一個一個のタンパクやRNAがどう作用しているかのネットワークを記述するのは、まさに駅すぱあと(鉄道路線検索)というソフトと計算は同じなんですけど、濃度がものすごく高い。どういう時にどれが発現されるかっていうのがインプットされるからものすごく複雑なんですよ。組み合わせの探索になるんですよ。 |
| 立花 | それは組み合わせの探索みたいな、計算の方式としては。 |
| 林崎 | そういうようなものも出てくる。さっきみたいなクラスタリングみたいなものや、濃度の数も今までは18万個ですがあっという間に100万個を越えますから、濃度の数が倍になったら計算量はものすごくなりますから。だからこういうタイプのRNAの領域とそれをいれたネットワークを書く人のニーズを絶対入れておかなければいけないと思います。ものすごいパワーユーザーになると思います。 |
| 広報の方 | 生物系の先生の声が全然、反映さいれていない。我々の事務方のほうも... |
| 林崎 | 反映されていませんね。本当にあれでいいのかなって思いますけど。誰でもいいんですよ、そういうことを分かっている人がこういう目的で使いますよって項目を入れてくれればいいのですが入ってない。 |
| 立花 | いや確か入っていますよ。サブ何とかグループとかで。 |
| 林崎 | でも直接的な計画として、名前はどうかは別として、こういうことをやりますよっていう中には欠損、欠落が山のようにありますよ。でも国がやっていることだし、どうかなって見ているけど。 |
| 立花 | ぼくは理研が中心になっているから内部で相当、意見のくみあわせをやっているものだと思いましたが。 |
| 林崎 | 意見のくみあわせはしていますよ。ただ姫野さんがどうなっているかわかりません。理研として言っていることも、どうなのかなーって生物系の人は言っています。 |
| 立花 | もともとは計算科学の世界の人ですからね。 |
| 林崎 | そうなんですよ。それ主導でやっていますからね。彼らは計算機をつくるための計算をやっていますから。 |
| 立花 | そうですね。 |
おわり

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
準備中