イントロダクション- ゲノム科学研究へのきっかけ
| 林崎 | では始めましょうか。 |
| 立花 | まずは自己紹介からしましょう。 |
| 学生A | 東京大学・工学部化学生命工学科三年の岡田ともうします。立花ゼミではRNA企画の担当と他に人工臓器学会大会の担当をしております。 |
| 学生B | 東京大学・農学部水圏生産学科の野村と申します。このRNAの企画にも入っておりますし、NPO法人のガリレオ工房の連携企画にも入っています。 |
| 学生C | 東京大学・教養学部理科一類の一年の川口と申します。生物には興味があって、今日は面白い話がRNAについて聞けたらいいなと思っています。よろしくお願いします。 |
| 林崎 | よろしくお願いします。ではRNAの話に移ります。 最近RNAの話題が沸騰していますね、それはなぜかというとわれわれの発見があったからです。もうひとつの大きな発見がRNAiです。その二つが同時に起きた。世界の中で大きなイベントの一つを私たちが担ったことをスライドで紹介しようと思います。私たちの研究を紐解くよう感じです。あと今、我々がやっているRNAはあるところまでいってまして、別の方向から技術転換が起きていることを紹介しようと思います。 スライド1 このロゴマークは実は我々の研究グループが1995年に理化学研究所のゲノム科学研究室というのが今の中央研究所のあったときからのものです。理化学研究所には主任会という大学の教授会に似たものがありまして、ただし学部別じゃないですね、自然科学すべてが集まっているものがあります。 |
| 立花 | それは全部ですか?素粒子から何もかも? |
| 林崎 | 一緒です。隣に座っているのが情報科学の人だったり、化学だったりします。私はもともと大阪大学の医学部を卒業して医者をやっていました。外来患者も入院患者ももって患者を診ていました。 |
| 立花 | 科類は何だったのですか? |
| 林崎 | 科類は内分泌科でした。ちょっとこれは個人情報を含んでいるので言うのか迷いますが、私がちょうど(大学)五年生の時、ちょうど病院を研修でまわっていたころ、突然、姉のところに電話がかかってきました。姉は私より七年半上なのかな、その時子供ができたばっかりだったんですよ。電話の内容は、すぐ来なさい、と。その理由はある新生児のスクリーニングというのを全世界でやっています。その中にある7項目の内の1つにTSH、甲状腺刺激ホルモンという脳下垂体から出ているホルモンがあります。その分泌が非常に高い。それは甲状腺の機能が弱い子供がそれをもっと刺激しようとしてTSHが出てくる。TSHをスクリーニングすることのよってクレチン病がある。クレチン病というのは、当時はクレチン病をスクリーニングする前までは全国の精神薄弱児の施設の半分以上はクレチン病だったんですね。知能が遅れていたり体が小さかったり、甲状腺機能が産まれながら低い子供はそうなります。その精神薄弱児を治す方法は産まれてから3ヶ月以内に気付いて、人工的に甲状腺ホルモンを含む医薬剤を投与すると正常になります。その時に脳のシナプスが形成します。産まれて三ヶ月以内がキーポイントなんですね。そして治療するのに薬代1日1円しかかからないので1年で365円。たったこれだけで精神薄弱が治るんですね。その電話の内容を聞いた姉は驚きましたね。今まで助からなかったものが治るわけですから。僕はその時、五年生だったわけですがこれは役に立つなと思った。それ僕の姪にあたる姉の(クレチン病の疑いのあった)子供はどうなったかというと正常に育ちまして今、歯医者をやっております。 スクリーニングを作った先生はちょうど私が入った研究室の宮井先生です。宮井先生はノーベル賞をもらったヤーロウというラジオイムノアッセイ(放射免疫測定法)という計測する方法を開発した人のところにHarvard Medical schoolへ行って、留学して帰ってきて日本で初めてTSHのコミュニティーを作って厚生省に働きかけて全国版をつくった人です。これは役に立つなと思ってその人のところに行ったわけです。スクリーニングをやると日本では7000人に1人が精神薄弱児になります。だから偉大な教授は施設にいってスクリーニングして助けようしたわけです。そのスクリーニングの過程で産まれながらにしてTSHが欠損している子供が見つかった。当時それをクローニングする技術なんてありませんでした。ですがちょうどその時、大阪大学に松原謙一先生の細胞工学センターができまして私は大学院の時そこに入った。そしてまだ誰もやってなかった、TSHの遺伝子を単離して配列を決定しました。それが私の学位論文です。そしてその遺伝子にミューテーションを見つけてそれが病気の原因であることを見つけました。さらにタンパクが異常な構造をとることを見つけました。それがおそらく日本で初めて人の病気のミューテーションを見つけた例だと思います。それで面白いなと思ってこの世界に入ってきました。 でも1個の遺伝子を見ていてもしょうがないと思って全部見てやろうと、ちょうどその時、ゲノムプロジェクトが出ていたころで若さゆえでそのようなことをやろうという方向に行きました。それが私の背景です。 |
理研・ゲノム科学研究の再建
| 立花 | それはアメリカのゲノムプロジェクトがどのくらいの段階のときですか?というより、ここの研究所(ゲノム科学総合研究センター)はあの先生が始めたんですよね?誰でしたっけ? |
| 林崎 | 和田(昭允)先生です。和田先生は当時、1980年のはじめ、ゲノムプロジェクトの大要に機械化というアイデアがまったくなかった時代に、システム工学を使おうと言い出した最初の先生です。日本はそういうのが得意で、例えばトヨタなどの自動車会社はパイプラインにのせて生産するというシステム化を行っていました。まさにここのセンターの初代所長にふさわしい人です。その後ぐらい、1982年に僕は医者になりまして1983年に本格的に研究を始めて1985年に最初の論文を書いて(博士課程を)卒業しました。今はだから49歳です。 私はそういう背景をもっていますがちょうど1994年に理化学研究所に着任する前に国立循環器センターに研究員としていましてそこでゲノムを高速にスキャンする方法を作りました。ゲノムのどこが欠損しているかだとか3000点いっきにでる方法です。当時はそういう技術が世の中になかったので結構注目されたのですが、日本だとそんな卒業したての若い人にはお金をくれないじゃないですか。でもゲノムプロジェクトが始まったばかりのころでマップを300点ぐらい置いたころに3000点が二週間で出来るような方法を作りました。それをなぜ使わないのか?でも日本じゃだれも言うことを聞いてくれないのでだれかに聞いてもらうとした。それでワトソンに直接電話したんですよ。僕はこんな技術を作ったけどどうだ?て言ったら、来いと言われてアメリカまで行った。そしてこのようなものを作った、と言ったら、これはすごいけど残念ながらアメリカは日本に出資したことがない。唯一の例外はサンガーセンターだ、と言われて結局帰ってきました。 それでこの価値を最初に認めてくれたのは当時、東京大学医学部の生化学の教授だった村松正實さんだったわけです。彼は今、埼玉医科大学のゲノム医学研究センターの所長をやっています。彼が僕の技術を見つけてくれて、さらに応援してくれたのが当時、国立がんセンターの杉村隆先生でした。それで和田先生がAutomated Sequencer、高速シークエンサーをつくっていたのですがそのシークエンサーは1ベース(塩基)も読まなかったんですよ。お金を使って失敗したからいろいろ言われて委員会で批判されていました。たまたま村松先生も委員で評価する方で理研はけしからんと言っていました。でもけしからんと言っているだけじゃしょうがなく、理研を建て直さないといけなかったので血を流しながら残った研究員を切って(解雇して)いって、代わりにだれかをたてないといけないということで僕を連れてきてくれたのです。1994年にゲノム科学研究室という主任会の一研究室に着任しました。 それで私は、筑波にいたのですが、ゲノムを筑波のセンターの旗印にしようと思って、我々の研究室が中心になって動きました。 |
| 立花 | おいくつのときですか? |
| 林崎 | 36のときです。その時はどん底だったけれども、そのぐらい若かったからできたのだろうね。アメリカの研究は進むと同時に失敗した時だったし、アメリカからはシークエンスをやれと圧力がかかってくるし、日本の政府は資金をどうしようと慌てだしていた時だったし。もっと早くやれば良かったのに。 |
| 立花 | それは何内閣の時でした? |
| 林崎 | 何内閣の時だったかな?最初の科学技術基本法が出来た時だから、1995年、まだ橋本龍太郎さんの前だから誰だったかな?(注:1995 年・村山富市内閣) でも当時の科学技術庁長官だけは覚えています。なぜなら着任したときに(理化学研究所の)理事長が有馬先生だったんですよ。理事長室に呼ばれて他の主任研究員は、君はクウォリティーの高い仕事をしなさい、と言われる。でも僕の場合はゲノム(科学)を改革しなさい。それがミッションなんですよ。それで翌日に筑波センター長の高橋信孝さんいていう前の東大の農学部長だった人なんですが、その人が、君、明後日いいか?と言うので、はい、と言ったんです。そして当時の科学技術庁室に連れられていってどこに行くのかなって思っていたら大臣室に行ったんですね。だから相当、理研はプロジェクトが止まっていて困っていたのだと思いました。長官の耳にも入っていたのでしょう。その長官は実は田中眞紀子さんだったんですよ。田中真紀子さんのところに連れて行かれて挨拶しなさいと言われたので緊張して肩をふるわせながら、よろしくお願いします、って言いました。そしたら機嫌がわるいんですね。なぜ機嫌が悪いかといったら最近、H2ロケットが落ちたばっかりだったんですね。 さて着任した後、何をしたかというと、ふと見ると君らも唖然とするかもしれないけれども教授職とかプロジェクトディレクターていうのは全責任を持っている。うまくいった時は誉められるし、失敗した時は叩かれる。人事権から予算決算権まで全職権まかされている。そうなるとちょっと世界が変わってくる。そうすると必死に考えますね。しかも失敗したプロジェクトとか見ていますから尚更必死になりますね。さあ自分で何かをしなくてはいけない。そしてふとアメリカを見るとゲノム科学だ、何でもいいから旗印だせと。それで起きたのはNIHがあと8年でヒトゲノムを解読完了すると宣言した。他国が入ろうが入らまいが自分たちでやると、入るのだったらどうぞ、という感じで。ということは2003年までに終わるということは確定したわけね。そうなったら日本の役目は何だと思った。それでその時Scienceにある論文が出て、フェノフィルスインフルエンザというインフルエンザの菌がありまして、肺炎を起こす菌。その菌の全ゲノム配列が完全解読されたという論文がでました。それは他に寄生しない生物で初めて全ゲノムが解読されたんですね。それさえあれば生きることができるわけです、種を残すことができるわけです。そのゲノムの解読をクレイグ・ベンターという人がタイガーという研究所でやったわけです。ベンターはNIHを飛び出してベンチャーを建てて民間の力でヒトゲノムを解読しようとしました。 それからアメリカはシークエンスを決定するのに民間と国の闘いになったわけです。それでクリントン・ブレア宣言というのが出てヒトゲノムの配列というのは人類共有の資産だから特許は取ってはいけないと言いました。ところが一方、セレーラという会社が特許を取ったりしていました。そういう闘いになっていました。結局、セレーラはそれでは金にはならないということで別の方向に走っていきました。 そのようなわけで、ヒトゲノム解読宣言をした後、インフルエンザ菌の全ゲノムが分かった。その時に出てきたのが、インサイトとかタイガーといったメガファーマ、巨大製薬企業に支えられたベンチャ−がヒトのcDNAのかけら、Expression Sequence Tag、ESTというのをシークエンスして特許を取り始めた。それでヒトのESTが飽和しつつあると言っていた。We have all、なんて言ってました。今から考えたらとんでもないことですがね。 そういうのが私が着任したときの状況です。それで私が考えたのが、私の趣味なんですが絶対、人とは同じことをやらないぞ、と思った。アメリカはヒトゲノムをやっているけれども絶対同じことはしないぞ、と思った。国際貢献するのは同じことなんですが、今、(ゲノム科学研究)センター長の榊さんはヒトゲノムの6パーセントをやったと言っていますが、それが大きいか小さいかは別として日本の貢献度は6パーセントでした。ほとんど理研の先生がやりました。それで95年に私が決めたのは完全長cDNAをやることにしました。cDNAって知っている? |
| 学生A | RNAからDNAを合成したもの。 |
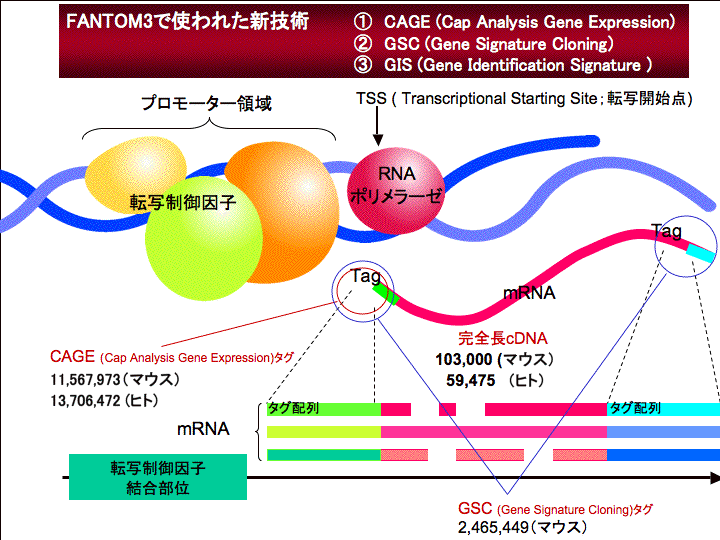
| 林崎 | そうそう。RNAに相補的なDNA、cDNAね、でそれがESTというのはかけらだったんですよ、ところが一続きのRNAの全長をもつcDNAを合成する技術なんてなかった。 で、例えば人とかマウスとか高等生物全部集めて全部シーケンシングしようと思ったら、許しがたいリダンダンシー(過剰性)、同じ組織からおんなじクローンがとれるcDNA、例えば、すい臓からだったらアミラーゼとかリパーゼがいっぱいとれたり、肝臓だったらアルギニンがいっぱいとれたりしますよね。 同じのが何個もとれるのは、まず回避しないといけませんから、完全長を取る方法はどうするかとかね、そういう技術的な山がいっぱいあると同時にアメリカは技術的に手が出なかった、技術的な山があるために。意図的にそれを狙います僕らは。 スライド2 私、トランスクリプトーム。オームというのは、総体をいいます。遺伝子はジーンっていいますね、遺伝子の総体、ゲノーム。トランスクリプトというのは転写物、ゲノム、要するにDNAからつくられたRNAのことでそのトランスクリプトのオームですからトランスクリプトームというのですが、蛋白もそうですね、プロテオーム、なんでもかんでもオームをつけっていってるんですけど。 |
| 学生A | 最近の流行なんですね。 |
| 林崎 | そう。それでトランスクリプトームをなぜ研究したかというと、要するにゲノムの中に何が書いてあるかがわかるんですよ。で、当時ゲノムゲノムと、アメリカはゲノムの方へいったけど、少なくとも日本のゲノムプロジェクトである理研ゲノムはですね、そっちの方へいこうと、逆の方へ行ったわけですね。もう一つは完全長のcDNAバンク、クローンを... クローンってわかる? |
| 学生A | ウェットな実験はまだやってないんで見たことないです。 |
| 林崎 | 後で見せてあげますよ。そうゆうバンクというのをつくります。というのは大腸菌一匹の中に一種類のヒトのcDNAを入れて、その中に大腸菌の一群の大腸菌何匹もいますから、そこの中にいれて増やしてる。ヒト、マウスのcDNAを同じもののコピーするんですね、それをクローンといいます。 一つのゲノムから何匹も同じ個体をつくること、大腸菌のクローンはcDNAのクローンバンクをとる。すなわち人やマウスのcDNA、全ての遺伝子、RNAをバンクにして、プレート一個一個の異なる穴にアイソレーションさせて、これらの何とか遺伝子、何とか遺伝子とか、全部のセットを全部番号作ってシーケンスを決定して、結局どんな遺伝子がコードされているかわかるし、それをゲノムとの配列を比較して、どっからでてくるかっていうのがわかるし、配列を比較することでわかる。 フルレングスcDNAクローンバンクというデータベースです。それは世界のグローバルスタンダードな21世紀のライフサイエンスのグローバルスタンダードで、今世界のみんなが我々のを使っていますよ。コンピューターサーバーとかDDBJとかジェンバンク、そのデータベースのバンクがありますが、少なくとも我々のデータベースに一日24時間、一年365日、少なくとも5秒に一回は使われている、それだけ非常に重要であります。なぜ重要かというと蛋白ができるからです。完全な一つながりのDNAは蛋白質を合成できます。かけらじゃできない、だからものすごく重要なんです。全てのライフサイエンスを行なうための基盤となる。後もう一つはフルレングスcDNAのアプローチで、選択的スプライシングって習いました?エキソンってあるでしょ? |
| 学生A | 場合によってとられるところころが違う。 |
| 林崎 | そうそう、あるとこがとられたりとられなかったりするでしょ、それをみる時に、あるところだけみても、どのRNAがコードしているところがわからないんですよ。 それをみようと思ったら一個一個フルレングスcDNAをとってアナリシス(分析)するしかないんです。 あと最近流行っているのがsmallRNA。RNAiということばを聞いたことがあるとおもいますが、RNAiがやるときにどうしてるかというと、どんなものがRNAiのターゲットとなっているかを探そうと思ったら、フルレングスcDNAクローンバンクを使って合成するしかないんですよ。このアプローチはめちゃくちゃ重要なアプローチと信じました、当時。実際それで、これを実行しました。 私はそれを理研でやったんですが、今や、ここに和光研究所に理事長がいる本部があります。野依さんがいますけども、当時は僕は筑波におりましたが、結局ライフサイエンスのために横浜研究所にうつすことにしました。 |
国際コンソーシアム・FANTOM
| 林崎 | スライド3 これは私の研究室ですけど、外国から(研究者が)来てますが、後で話ますが、FANTOMの基盤になっています。そしてこれは神奈川県知事の松田さんですね、今日はもう,立花先生がいろいろ既に書かれている(ゲノム・コード)ので、プロフェッショナル用に使うスライドを使ってます。 これは何を言っているかというとヒトの細胞からとってきたRNA、トータルRNAを電気泳動する。ここら辺に縞が見えるのわかります?この縞はある特定のRNAのポピュレーションがあるんですけども。ここが有名な28sでここが18sでリボソームRNAね。 実際ですね、我々が一番最初にスタートするのは蛋白になるところが欲しいってだれでも思うわけですよ。だからこの辺、真ん中辺をばっととってきて、この辺をクローニングしたんですね、いっぱい。で、これ冗談で出しますけど、スーパーヘビーからフライ級までボクシングのあれなんですけども、なんでこんなことしたかっていうと、miRNAみたいに小さいけどヘビー級のRNAをノックアウトしようと。ボクシングみたいだからこういう名前をつけたんですけど。とりあえずまあここに注目したわけですね。で、時は1995年なんですが、アメリカがそんなこと(全ヒトゲノム解読)いったので、こんちくしょう、私はこっちへいくで、と我々はこっちに舵をきった。それが私が着任して最初に決断したことです。アメリカが向こういったから日本はこっちいこうとcDNAやったわけですね。 cDNAでやる一番重要なポイントはですね、新しい技術の壁があるからアメリカはやらなかったんです。技術の壁がなければ、あのような国っていうのは、アメリカの研究費のことはもうご存知だと思います。例えばね、僕が着任したときのNIHの予算を調べたんですけど年間263ドルあったんですね、3.3兆円ですよ!日本の総合研究予算は4千億円くらいですよ。DOE、Department of Energy(米エネルギー省)を含めたら倍ぐらいあるでしょうね。 そしてNSF(米国立財団)もある。さらにハワード・ヒューズのようなPrivate Grantもありますから、多分思うんだけど日本の予算の30倍以上持っているじゃないかなぁ。それからドクター出の研究者の数も18倍くらいある。だからテクノロジーの壁があってできないというもの以外、お金を投資してやれるものはブルトーザーのように押し切れてしまう。もう野獣的な力ですよね。そこで戦ってもダメ。でヒトゲノムって多分そうなるだろうと思った。 スライド4 ところが完全長cDNAだけはね、シークエンスの技術がなんぼあってもね、DNAがなかったらシークエンスできない。だから完全長cDNAのところをおさえると、多分そこだけでまず自分の地位を築けると思った。で、考えたのが、一つのフルレングスcDNAの合成するシステム、アッセリーゾーム、これ重要なことで、一個の技術ではダメなんですよ。これはマウスでやりました。何でマウスかというと、ヒトはゲノムのDNAにするのは白血球という場所からとるよね。例えばcDNAだったらさ、RNAとらなきゃだめでしょ、RNAは発現している組織があるわけ。同じゲノムだけど、例えば神経だったら神経特異的なRNAが出ている。例えばチャネル遺伝子とかいっぱいでてるね。さらに例えば受精卵の時に発現している遺伝子があるよね。人間から受精卵2万個集めるのはムリでしょ。まず倫理的に問題があるから。倫理的な問題がなかったとしても、受精卵を2万個集めるのは無理ですから。そうゆうのを考えたとしても初期発生とか、そんな時期のものを使うのもムリだから、マウスを選んだ。 スライド5 で、当時このマウスエンサイクロペディア、百科事典なんですけど、95年の段階です。まず、技術を開発しようとその技術をつかって、マウスエンサイクロペディアを作ろうとしたんですが、当時は気違いみたいなプロジェクトでして、フルレングスcDNA合成するということですねぇ、シークエンサーといっても、ガラス板二枚はさんでゲルを注入するやつしかなかったんですよ。で、そんなもんでやっていたらね、自分で計算したんですけど、当時ABI社が売っているシークエンサー、5000台いるんですよ。わかると思うんですが、研究者がね、ノーペーパーで2年間過ごすのは待てないんですよ。多分去っていきますよね。そうすると逆算するんですね、一台のシークエンサーのすることを考えると5000台いります。5000台を収容することを考えると、東海道線のような鉄道かいて線路沿いにずーっと並べて貨車にのって(一台一台)やっていく、こんなこと考えないとできないんですよ、経済的にもまったくナンセンスですねぇ。 それでシーケンシングテクノロジーそのもので、逆算すると一日で...(大腸菌プレート登場)これが大腸菌のクローンです。こっからすぐわけちゃだめです。ポツポツってわかるでしょ。このポツポツは寒天の上に大腸菌が着陸してそこから増えたものなんですよ。一個の点々ありますよね、一個の点の白の点は一匹の大腸菌が着陸してそこから増えてきたクローンなんですよ。青はね、マウスやヒトのcDNAはいってないんですよ。白が入ってるんです。 |
| 学生A | 青はなんのためにはいってるんですか? |
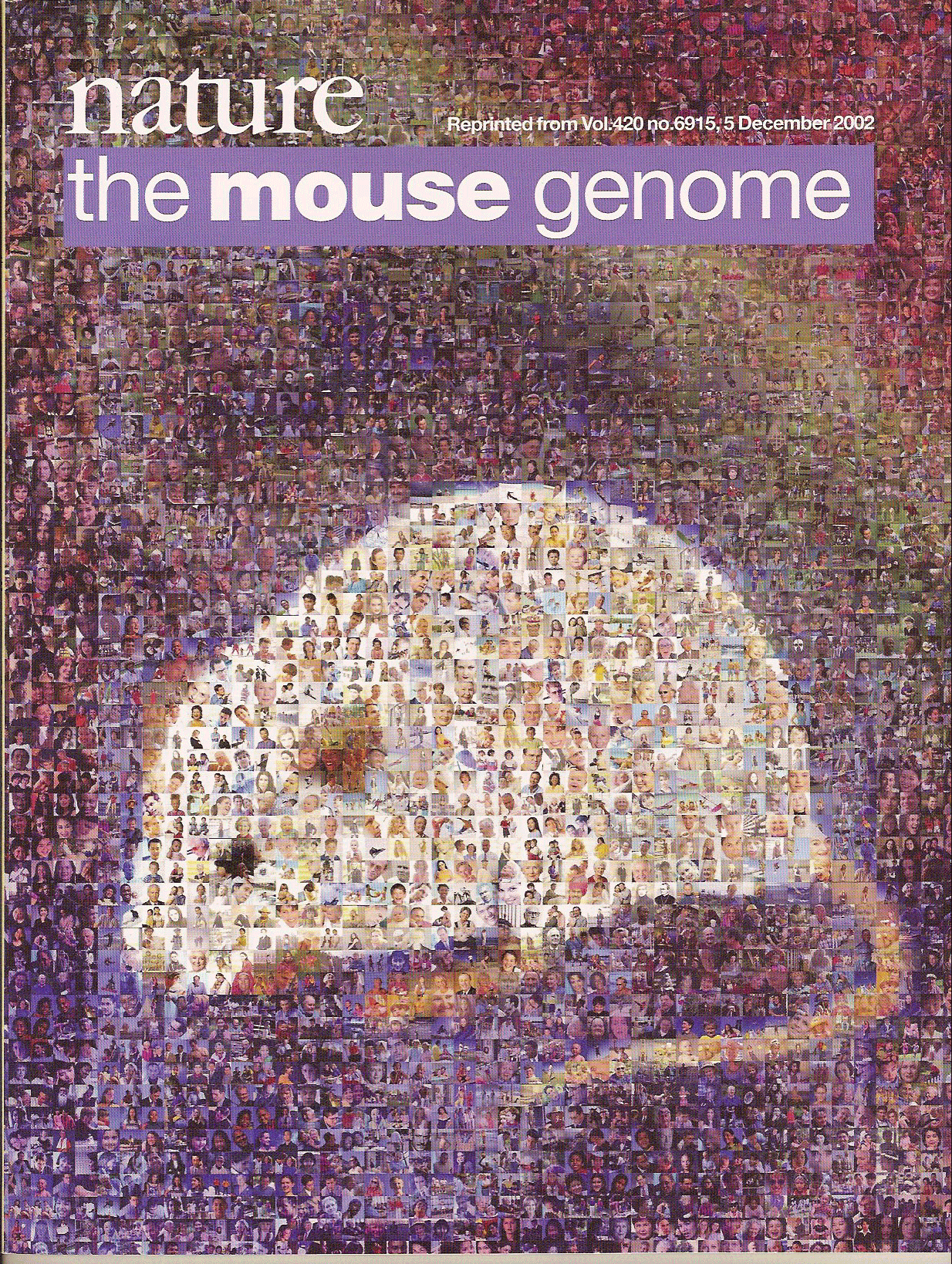
| 林崎 | 青はね、cDNAが入らないと、青い色を呈するような基質があるんですが、その基質が入った時だけ代謝の前の物質がある酵素に代謝されて、青色の代謝産物を作らないので、白色のままになると。白色の部分だけをピックアップして、大腸菌が取れる、というわけです。あとででてきますがFANTOMというアノテーションシステムなんですが、これを後で説明します。 この技術を使ってマウスの百科事典を作ろうと。百科事典は当時考えたのではこれには五つのコンポーネントがあります。一つはクローンのバンク、そういうのを一杯集めて。それからそのシークエンスのインフォメーション、すなわちデータベース。それから染色体のゲノムの配列のどっからきてるか。それから発現プロファイル、いつどこでそのRNAがでているか、受精卵で出てているのか神経細胞で出ているのかそういう話。あとは蛋白の相互作用。 スライド6 完全長cDNAテクノロジーというのはですね、完全長cDNAを合成する技術ですが、これはもうものすごいたくさんの基礎技術がある、これ全部特許とってきました。アメリカの商業的な追撃をおさえるため。このcDNAテクノロジーだけでも特許数が30超えていると思います。 キャップトラッパーっていう完全長cDNAだけを選択してくる、途中で止まるんですよ、cDNA合成したら。止まったヤツを除く技術ね。完全長までに逆転写酵素がのびないとお話にならないわけですね。逆転写を伸ばすために、普通どうなるかといったら、電話のコードってさ、例えばこれをRNAとしますよね、RNAは二次構造をとるんですよ。二次構造とるには例えば温度を変えたら安定になる、この一番端っこから逆転写酵素がきてここでとまる。ひもだったら両端引っ張ったら伸びるよね。RNAそういうことするわけにいかないから、どうしたかといったら温度を上げたらいいんです。しかし温度を上げると逆転写酵素が失活しますよね、じゃあどうしたらいいかというと耐熱化してます。耐熱化する酵素。トレハロース。2糖類があるんですけど、お砂糖入れると至適温度、反応度が20度上がる。これっていろんなもんに応用できます。cDNAっていうのは、例えば筋ジストロフィー症って難病な遺伝子あるでしょ、遺伝子の長さが14キロなんですよ。 14キロの遺伝子丸ごとすぽっととりだして大腸菌のなかにいれても安定に保持しないんですよ。安定に保持する方法として、新しいスーパーロングcDNAベクターをつくってみたりね。これF因子という大腸菌だけにいれるDNAのベクターなんですけど、これを応用すると長いものでもどかっととれるし、それから、ハイスピードシークエンシングテクノロジーこれ、一日4万個をこなさないといけないわけで、大腸菌のそのクローンね、一日に四万個処理しなければならない。 95年に一日四万個毎日毎日つくるぞっていったら、バカ呼ばわりされて、でもつくらなきゃしょうがない、これをつくらないわけにはできないんですね、だからそれをやるためにはどうしたらいいかって考えたんですね、で大腸菌をピックアップしてプラスミドをとって全自動でDNAをとる機械とかですねえ、それからPCRを全自動でやる機械とか、シークエンサーで一日4万個やるために、シークエンサーなんて当時セレラ社というのが98年にできましたけど、96のキャピラリーシークエンサー、ガラス最短を用いたものの4倍のキャパシティーをもっているものを一年前から使いはじめたんですよ、一番進んでたんですよ。で、実際コレでシークエンスをばっとやってみました。そうすっと配列がばっとでてきました。するとこんなもんがでてきました。よくわからんでしょ。ようするに生データを理解できませんと。で、どうしたのかというと国際コンソーシアムをつくりました。FANTOMといいます。ファンクショナルアノテーションマウスDNA。当時マウスのcDNAでしたし、注釈付けのことアノテーションといいます、機能注釈をつけるものですね。 スライド7 FANTOMという国際コンソーシアムの名前です。これをやってですね、でてきたデータを全部でつくったんですよ、みんなよってたかって国際スタンダードのデータベースをつくろうと。 一個目の発表はですね、ヒトゲノムのドラフトシークエンスが2001年2月15日にでましたけど、一週間前の2月8日にネーチャー誌と組んで意図的にこのときに出します。一週間前でないとヒトゲノム配列を解析するのに僕らの配列を使ったんですね、私らのを先にださないとヒトゲノムが出せないわけです。 この表紙しらない?世界で始めてヒトゲノムのドラフトシークエンスを出した最初のものです。(画像1) ヒトの配列が、要するに我々自身の暗号がどんな形をしているかを全部みた。ゲノムのシークエンスをしたほうがいいんだけど、実際どこがRNAなのかわからないわけ。だから、僕らのマウスのRNAを用いて、ここだというのがわかったんですね。もっともっと解析を増やしていきますと、Natureにでてたマウスゲノム特集号(画像2)なんですけど、そういうものが当時でました。これあの、マウスゲノムとcDNAが一緒にでたんですよ、これ結構有名でcDNAとゲノムが同時に両方解析されたのはマウスが最初の生物なんですよ。この方法めちゃくちゃ有用ですよねえ、ということで、実験植物のシロイヌナズナ、それがこの二つね、後もう一つ、今、植物センター長の篠崎先生とスクリプスのジョー・ウィッカ先生の共同研究で、これはですね、役に立つということでササニシキ、皆さん食べてる、これのcDNAをやった。農業資源研究所と国際科学振興財団との産学プロジェクトです。 で、このFANTOM2の方は二番目の会議なんですが、2003年にまとめたものなのですが、まるごと(論文)29本を一冊丸ごと借り切って、こういうようなやり方が、僕らみたいなグループが出てきてからですね、普通論文って一本ずつだすじゃないですか、丸ごと借り切るんですよ、ジャーナル一冊。(画像3)これはみんな驚いたと思うんですけど。 これがヒトゲノムです、私らは脇役です。この人たちは僕らのデータを使いました。でね、この穴あるでしょ。この穴の一個一個は一種類の大腸菌をぽつんとおいて、だから一個の中に一種類の遺伝子が入っている。16×24の384個の穴があるんですけど、たくさんの穴を集めたのがcDNAバンクです。後でラボツアーするときに−80℃のところを通ったら見えますんで。 |
| 学生A | 一個一個全て違うんですか。 |
| 林崎 | 一個一個全部違う。 スライド8 次なんですけどFANTOM3というもので、これでできたものは結構すごくて5秒に一回アクセスがある。今見たプレートが山のように積んであります。−80度のところに全部バンクしてある。 で、それでそこのところに全てのライフサイエンスする人に必要なクローンが、高血圧だとかガン、糖尿病などのクローンがある。これがスタンダードなのです。これ、データはデータベースとしていったわけですね。 でもみんなクローンを頒布しなければいけない。で、新しいこと考えて、クローンを頒布しようとおもったら、今クローンは10万個あるんですよ、それでね、データベースはクローンバンクなんですけど、6万7千個ですが、FANTOM2の時点だとFANTOM3になると10万近くなります。6万個ぐらいだとね、外国に運ぶとなると箱に入れてドライアイスが必要で、どんどんいれてくと100キログラムくらいになります。重いでしょ。しんどいでしょ。コストがかかるでしょ。途中で運んでいるうちにドライアイスはとけたらパーになってしまう。 それでどうするかというと、DNAブックって知ってます?これはね、DNAそのものをインクにして本に印刷したんですよ。紙の上にDNAが印刷されていて、郵便屋さんが運んで、ここだけくりぬいてPCRしたらDNAが出てくる。書店で売ることもできますね。 |
| 学生A | これどうやって活性を失わないようにしてるんですか? |
| 林崎 | それがみそなんですよ。 面白いことに、これFANTOM2の論文で、まる一冊僕らの論文なんですが、これの後ろに、“DNAブック”と書いてあるんです。今の話が書いてあるんですけど、ここにこういうページがあるんですけど、これTCAサイクル(クエン酸回路)なんですよ。(画像4)それの各酵素の本物のcDNAをここに打ったんです。だからこれ世の中に配布したんだけど、これパンチアウトして、PCRしたら増えてく。これが歴史上始めてDNAがほんとに印刷して出版された最初の本です。 |
| 学生A | これほんとですか? |
| 林崎 | それ本物や。 で、その後、今のページちょっと見てもらったら分かりますけども、パンチアウトしてPCRしたら、紙が水にとけてDNAがでてくる。今までとったやつ全部プリントアウトしようと思ったのがこれです(マウスのcDNAブック)。 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
準備中