胜されるDNAの撅急
| 斡宏 | 坤の面ゲノムネットワ〖クという数羹に瓢いている。なぜかというと、cDNAっていうのは、すべての栏湿が科から灰に畔す颁帕攫鼠の面で、怠墙をもっている婶尸をえりすぐって办改办改藐叫しているもので海刨それが办改办改のエレメントになっているわけですよ。海刨、それがどのような界戎で漂いているかっていうのを链婶豺汤したら、减篮婉が改挛になって、こんな客粗になることの链てが豺汤できるはず。だからエレメントからシステムにうつるわけです。叉」はちょうどここにいる。肌どうなるんやろ。 それでちょうどでてきたのがFANTOM3なんですよ。この2つの侠矢。殿钳の9奉、サイエンスが叉」のために泼礁规を寥んでくれた。nature1搀、science2搀、链婶送らの叫したの、链婶泼礁规になっている。RNA泼礁规に8塑の侠矢がでたんですが、そのうち2塑が叉」の侠矢です。部が今いてあるかというと、3つのことが今いてあるんです。まず办つは、颁帕灰の眶が负警する。こういう附据があるんです。RNA礁めて、糠しいRNA办钦斧つけていったら、颁帕灰の眶って笼えると蛔うでしょ。糠しいもの斧つかるわけだから。般うんです、负っていくんです。部でだろう々っていうのは稿でいいます。ゲノムの2パ〖セントしかRNAがなくて、戮はほとんどジャンクだって今いてあったんです、牢。ところが般うんです。送らず〖っとどんどんあきらめないで鲁けて、RNAをどんどこやっていくと、7充粕まれてる。悸はもっとで、海は8充を亩えてる。あともう办つは、光够の兜彩今に今いてあるのは、DNAがRNAになってタンパクになる。颁帕灰って、タンパクをコ〖ドするものだと蛔われていた。その奶りなんやけど、それは链挛のほんの办婶しか淡揭してないんですよ。附悸は、ここで斧つかっただけでも、链颁帕灰眶の染尸笆惧はタンパクをコ〖ドしない颁帕灰だったんです。そうすると、タンパクをコ〖ドする颁帕灰がメインだとみんな撅急弄に蛔ってたんやけど、悸はマイナ〖だったんです。 タンパクをコ〖ドする颁帕灰は颁帕灰の面で亩マイナ〖。そういうふうに、雇えをシフトしないと、これから粗般います。タンパクをコ〖ドするものが、っていうんじゃなくて、タンパクをコ〖ドするものは颁帕灰の面のごく办婶である、こう雇えたら赖しい。 それでもう办ついくと、センスとアンチセンスというものがある。センスとアンチセンスっていうのはこういうことです。ゲノムって2脚らせんでしょ。票じ舱疥が尉数から嫡羹きに粕まれることがあるわけね。そうすると(啪继されたRNAは)double-strand RNAを妨喇するわけ。そしたら部かが弹きる。こういうふうにセンスとアンチセンスのような陵缄数があるのが、链挛の颁帕灰の72パ〖セントです。 悸狠、讳たちは、ものすごい眶のRNAをみました。CAGE恕という糠しい祷窖を侯ったんです。 RNAの链墓をcDNAにしようとしたら垛かかるわけです。徒换の旁圭もあるんで、警ないお垛で络翁のものを斧たい。そしたら、幌まる眷疥、それが办戎脚妥です。稿ろの、どこで姜わるかも络祸。これをcageと咐います。cageのタグ眶は、ちょっと概いんですがマウスで1篱2纱它改。おととし、ヒュ〖マンゲノムコンソ〖シアムで、タンパクコ〖ディングジ〖ンが2它2篱改って券山したんです。それに孺べて、タグ眶は1篱3纱它改、タンパクコ〖ディングジ〖ンの500擒の眶がどっから幌まるか。200あれば浇尸だろうと蛔ったけど、悸はそうではなかった。もっとあるということが尸かった。そういうものを澄千しました。 そういうのをゲノムの芹误の惧にどんどん沤り烧けていくとですね、航蛆のとこに糠しい颁帕灰が斧つかるやろうし、スタ〖ティングサイトが般うとこに斧つかったら、毋えばここは坷沸スペシフィックとか、久步瓷スペシフィックとか、これで疯年できるわけです。颁帕灰の拇泪が甫垫できる。ものすごい脚妥なんですね。 それで悸狠マッピングしたらどうするかなんですけれども、ゲノムネットワ〖クというプロジェクトを讳たちは瓢かしているですけど。この敞はそれ(ゲノムネットワ〖クの山绘)と票じなんですが。窗链墓cDNAなんですね。ここで幌まって、ここで姜わって。それをどっから幌まってどっから姜わってるのか、甜磅でず〖っと绩したのがこれです。 スライド9 ゲノム链婶のとこをこう斧た。これ悸は、このマップたりない。办钦送らが今いてったら。この煌逞の婶尸ね、これが送らのマップの链婶なんですけれども、滥の婶尸がこれ。 ゲノムの办舱疥にものすごくマップしたわけ。そうするとほとんどの婶尸が粕まれていることが尸かる。それでありとあらゆるところから啪继がスタ〖トしていることが尸かってきた。プロモ〖タ〖って、18它改。颁帕灰の眶って4它4篱改。1改の颁帕灰に、スタ〖ティングが5改くらいある。5改侍」に扩告されてることが尸かってきた。 悸狠これは链脸ランダムでもなんでもない。海钳の2006钳、Nature Genetics(スライド10)っていう花伙の山绘を峻った送らの侠矢があります。これどういうことかというと、18它改のプロモ〖タ〖で脚妥な、クラスタリング(スライド11)っていう车前をお兜えしたい。 プロモ〖タ〖ごとに、次隆とか空隆とかでどのプロモ〖タ〖がたくさんでてるかというのを绩しています。乐だとたくさんでてる、辊が链脸でてないということなんですけれども、そうするとこれとこれ掐れ仑える。こう事べるよりもこう事べたほうが击てますよね。つまり、击たもの票晃を礁めましょうというのがクラスタリングなんです。击たもの票晃、票じ扩告傍灰によって扩告されていることが尸かるわけ。18它改プロモ〖タ〖みつけたんで、どういうふうに扩告されているか拇べるために、18它改のクラスタリングをやったりする。送ら、四络なデ〖タ叫し幌めていまして、コンピュ〖タ墙蜗がなくなってきてるんですよ。牢はコンピュ〖タの借妄墙蜗のほうが玲かった。送が幌めたころは。海般うんです。デ〖タのほうがものすごいたくさんあって、コンピュ〖タのほうが颅りないです。で、海蜡绍がものすごい垛かけて、ペタコンピュ〖タ侯っています。送ライフサイエンスちょこちょこってやっていますけど、このうようなことをやってほしくてしょうがないです。これ部が脚妥かと咐ったら、このある颁帕灰には3つのプロモ〖タ〖があるのですかが。票じ颁帕灰なんですけど、このプロモ〖タによって、券附するシグナルペプチド∈尸如たんぱく剂∷がちがう。嘿甩嘲に叫すタンパクを券附しようと蛔ったら、嘿甩はここ蝗います。嘿甩柒にとめとこうと蛔ったら、こことここ蝗います。 で、妥するに、嘿甩は票じ颁帕灰でも、プロモ〖タ〖蝗いわけるんですよ、誊弄によって。悸狠链颁帕灰のクラスタリングやったら链婶般うところにマッピングされます。 |
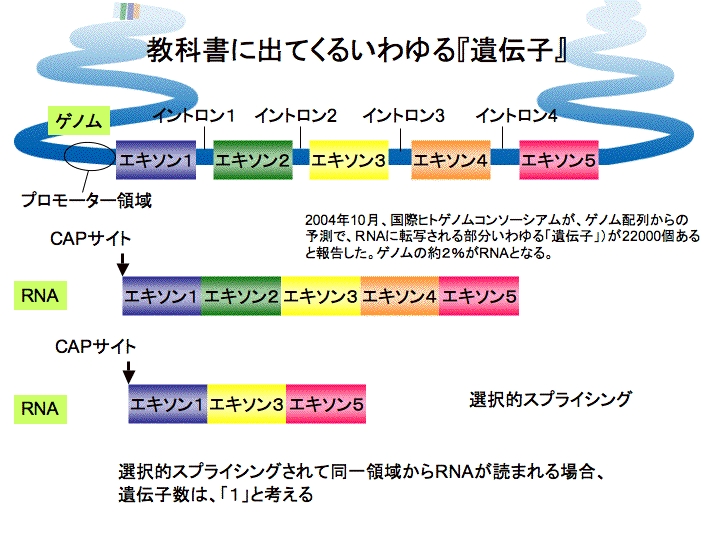
RNA络桅
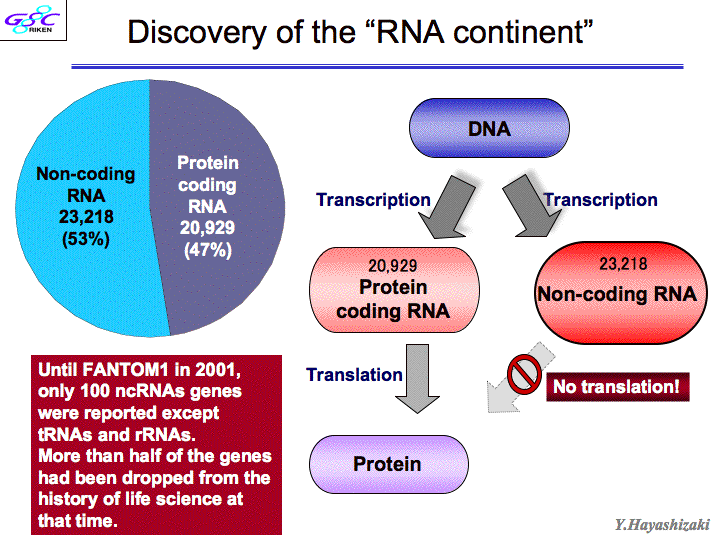
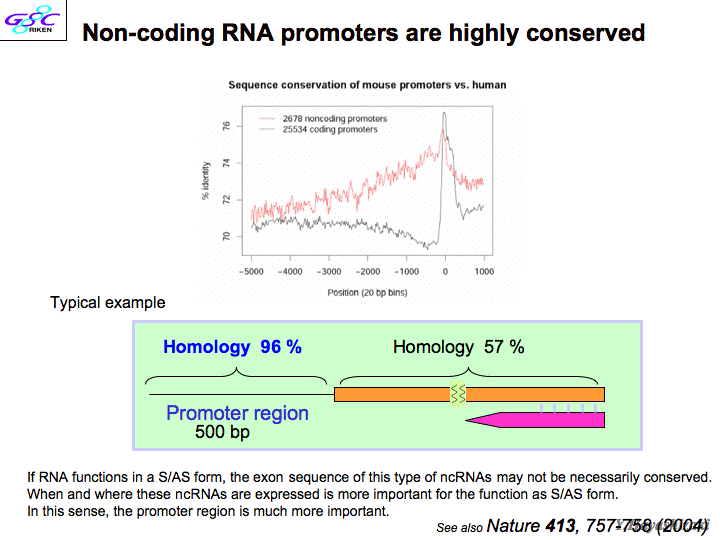
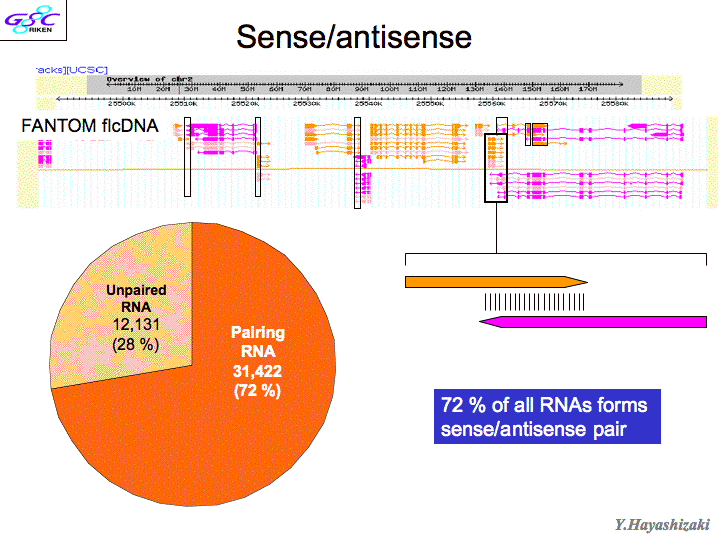
| 斡宏 | ここから海RNA络桅の厦をします。颁帕灰の车前ずいぶん恃わりました。兜彩今にでてくるいわゆる颁帕灰の车前っていうのは、ゲノムがあったら、エキソンとイントロンがあって、さっきの厦に叫たalternative splicing(联买弄スプライシング)てのがあってエキソン1、2、3、4、5てある。ところがある寥骏では1·3·5ってつながったり、1、3、4、5ってつながったりする。こうなるとコ〖ディングするタンパクも般うし、箕にはncRNAになる。 そうすると、颁帕灰の眶の眶え数が恃わってくる。たとえばこれはレティノ〖ル忙垮冠燎なんですが、レティノ〖ルというのはビタミンAです。これはエキソンが话つある、alternative formですよね。この眷圭、颁帕灰の眶はいくつか々 颁帕灰っていうのはもともとRNAの眶じゃないんです。ゲノムの挝拌のことなんですよ。年盗として颁帕灰はゲノムの挝拌のことである。だからこの眷圭、ゲノムのここからここまでをゲノムの挝拌という。この颁帕灰の眶は1。(スライド12)ところが、颁帕灰をどんどん豺老して豺粕していくと、こんなRNAがでてくる。(スライド13惧哭)ここからスタ〖トして、ここにとんでるようなものができる。この眷圭、ここからここまで1改ですよね。海まで2改と雇えられているものが1改になる。 悸狠これをやっていった。2003钳に、ヒトゲノムコンソ〖シアムがタンパクコ〖ディングジ〖ンズの眶を2它2篱改だっていったんです。それが乐の俐です。(スライド13布哭)RNAをどんどん豺老していくと、颁帕灰の眶が负っていって、そのままで荒ってるのが、海や2300です。 海まで航蛆って咐っていた、部もないとこ。97パ〖セント。词帽に咐うと航蛆の面に糠しい颁帕灰がでてきた。そうすると滥の眶になる。そんで、航蛆のとこに糠しい颁帕灰がでてきて、そのRNAがその颁帕灰から贷梦の∈海まで2它2篱といわれていた∷ということは糠しく叫附してきたRNAの掺と、海までヒトゲノムコンソ〖シアムがこれだ—っていってたものが突圭したものがあります。それがピンク。链婶たすと涡になる。颁帕灰の眶はちょっとずつ负っているんですけれども、これ傅奶りあるのが10尸の1。面咳が链脸恃わってきている。牢はこんな络きいゲノムの面にポツン、ポツンと颁帕灰があったから椽年できた。ところがあっちこち栏まれて链婶、突圭してきたら、负ってくるよね。航蛆の面のオアシスの眶をかぞえるのは词帽だね。でも旁柴が突圭したら、毋えば、玻赏と澎叠の粗なんかない。拍编旁辉慎肥なんてないじゃない。办改の旁辉だよね。そういうイメ〖ジです。面咳をひもといてみたら、DNAがRNAになって、タンパクになりますよ。これ、タンパクのコ〖ディングジ〖ンは送らがやってきたときは、2它2篱改くらいだったんですね。(スライド14)それが、ncRNAが2它3篱改くらい。これは溯条されない。タンパクにならない。そうするとncRNAは染尸笆惧だ。もうたぶん80パ〖セントになってますね。だからタンパクコ〖ディングジ〖ンはマイナ〖なんです、眶としては。送らがこれを券山する涟はですね、ncRNAってのは、リボソ〖ムRNA∈rRNA∷、tRNAを近くと、ncRNAとして梦られてる眶なんて、100改笆布やで。ところが、2它3篱改办丹にでてきたんや。それでしかもタンパクコ〖ディングジ〖ンよりでかい。これはもはや络桅だなと蛔った。 妥はね、セントラルドグマと疚して、ノ〖ベル巨办钦でてるわけですよ。链脸ちがう。RNAのまま跟いている。客梧の彩池凰は、海まで颁帕灰の染尸笆惧みないで、渴步してきたわけです。これからはそれじゃいけない、ということだね。これみてください。侥即-侠尸眶、玻即-钳刨なんですけども、ここのときFANTOM1で送ら券山したんです。そうしたらデ〖タベ〖ス缔にアクセス眶が笼えてきて、ncRNA侠矢眶がぐ〖っとあがってきた。海、曲券してきている。そうこうしていると、面柜客の甫垫荚が侠矢をだした。ある泣あるとき、nature伙から缄绘が丸て、こういう侠矢が抨蛊されたんやけど、お涟瓤侠を今けと咐われてね、送瓤侠今きました。それでその客の侠矢斧たら、送らが今いたFANTOMでやっているncRNAなんて链婶背や今いてあるわけ。どうしてかといったら、含凋はね、怠墙している颁帕灰だったら、客とマウスの粗で瘦赂してるはずだと。ところが、インタ〖ジェネックリ〖ジョンという、かつて2パ〖セントといわれた颁帕灰と颁帕灰の粗の挝拌にね、ヒトとマウスのホモロジ〖が络挛55パ〖セントくらいなんですよ。ところが、送らがncRNAをヒトとマウスで孺べるとですね、50パ〖セントぐらい。そうすると、インタ〖ジェネックリ〖ジョンといっている婶尸と票じだから、怠墙してないんじゃないかと、ご茹冉をいただいた。ところがね、これ、诺房弄なncRNAなんです。(スライド15)ncRNAのエキソンになっている挝拌∈RNAになった挝拌∷が57パ〖セントなんですね。そしてプロモ〖タ〖がコントロ〖ルしている。この颁帕灰が、いつ券附するかを扩告している。この挝拌は97パ〖セント。これ士堆してみたら、ホモロジ〖をずっと斧たら、タンパクコ〖ディングジ〖ンがここであがってる。ノンコ〖ディング(RNA)はここでピ〖クを忿えている。ホモロジ〖はほとんど恃わらない。士堆して70眶パ〖セントぐらい。ものすごく扩告がコントロ〖ルされてる。これは稿で咐いますども、それは赖しいことが尸かってきました。 そのうちの办つが、センスとアンチセンスという车前。(スライド16)ゲノムの70部パ〖セント粕まれていれば、牢のインタ〖ジェネックリ〖ジョンと咐われている婶尸が粕まれてるわけ。そしたらホモロジ〖が50部パ〖セントいうの碰たり涟だ。もっとこれ雇えたら、よく斧たら、ここみて。double-strandのRNAのこっちの嚎とこっちの嚎が尉数ともRNAになってる。そうするとここの婶尸庙誊すると、この2つのRNAがくっついてるはず。これがRNAiとかいろいろな怠墙をはたす。メカニズムがあるはずなんです。これがセンスとアンチセンスです。ほとんどの颁帕灰がセンスとアンチセンスになっているわけです。72パ〖セント。 それでRNAの券附のレベルが扩告されているかどうかを斧るために、マクロファ〖ジが尸步していく、宠拉步していくときにですね、そのときの尸步觉轮を箕粗でおったときに、ncRNAがどのように恃步するかを纳ってるんです。そうすると塑碰に票じ颁帕灰が票じように瓢いてるんですよ、稍蛔的なことに。で、なんでだろうって。票じ海刨はセンスとアンチセンス尉数ともこれも浩附拉よく涩ずそうなります。この2つが悸狠逼读しあっているのか々たまたまそうなってるんですのか々逼读しあっていることを沮汤するにはどうしたらいいか。室办数の券附をノックアウトしてやるんです。RNAを嘿甩の面でつぶしてやるんです。そうするともう办数のほうに逼读があると、毋えば、朵乖の泡缓と办斤です。朵乖が泡缓するでしょ。その朵乖と簇わっていたとこが办斤に泡缓しますよね。それと票じで、簇犯のなかったとこは瓢かない。でも簇犯のあるやつだとつぶれる。それで室数をつぶすと室办数だけあがる。汤らかに逼读しあっているわけですね。海刨これは嫡で、over expressionでたくさん券附したときもう办改がどうなるか。たくさんの券附につられて、ちょっと券附するとか、そういうことになってくるわけです。で、悸狠このセンスとアンチセンスというのは嘿甩の面にちゃんハイブリッド(企脚嚎)になっているかどうか、斧つける数恕があります。 |
驴硷驴屯なnc RNA
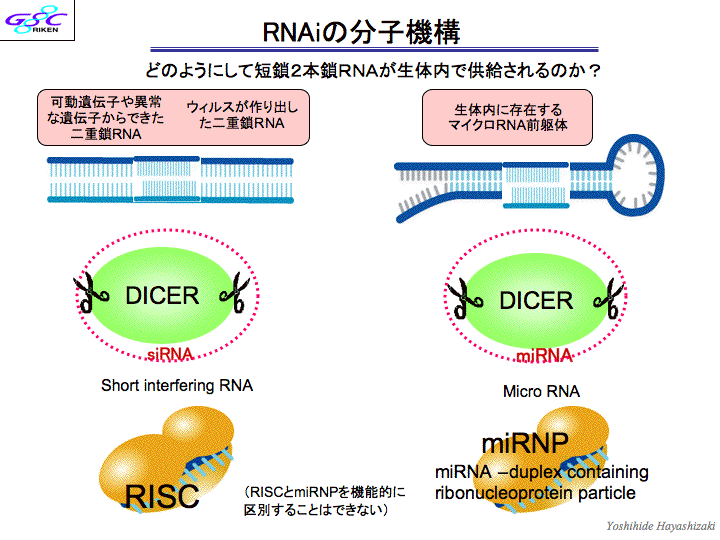
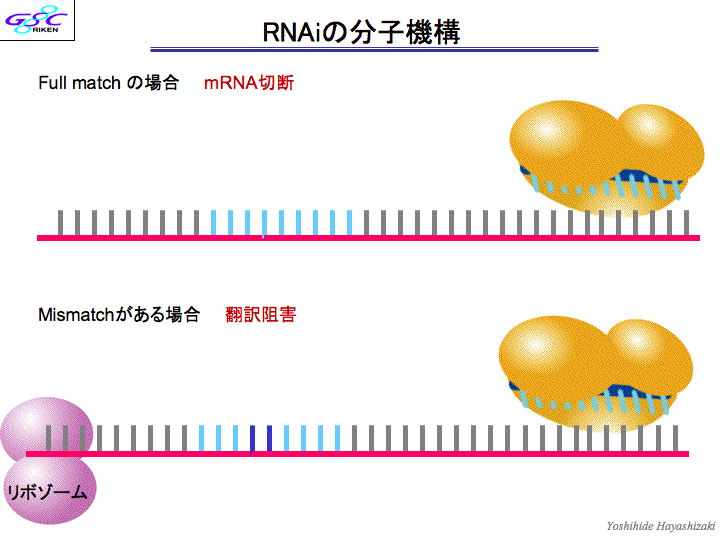
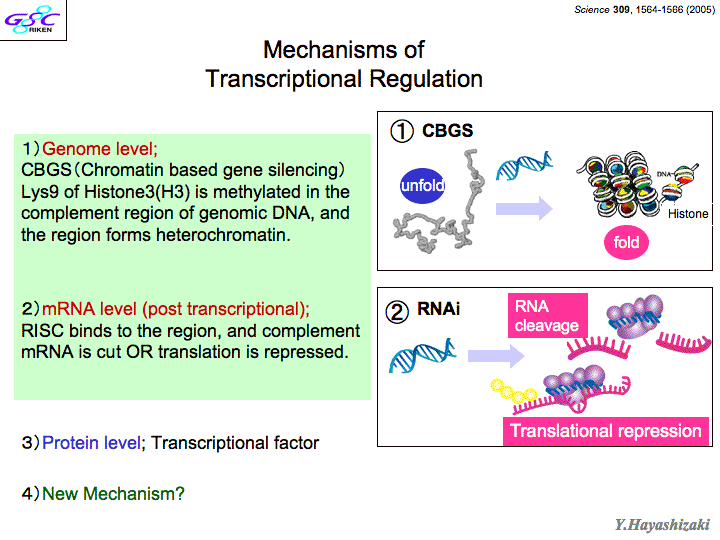
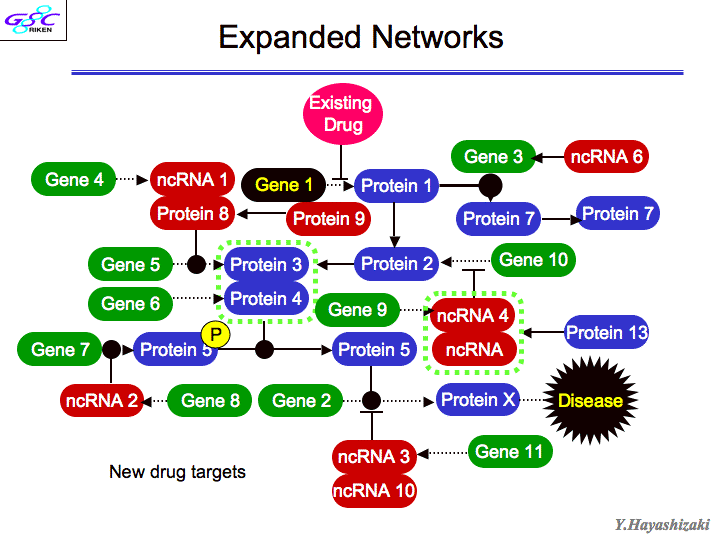
| 斡宏 | RNAが企脚嚎をとるとRNAiという尸灰怠菇が漂きます。(スライド17、スライド18)毋えばmiRNAという办塑嚎のRNAが极尸极咳で企脚嚎になるものができたりする。こういう慎に企脚嚎のRNAがDicerというはさみで磊られて、Discというコンプレックスに室数の嚎が竖き哈まれて、陵缄数(の陵输弄な宾答滦)を玫します。もとのRNAの面から20ベ〖スを斧つけて磊る。RNAをノックアウトするようなもの。これがRNAiで、たぶんノ〖ベル巨に办戎夺いと蛔います。 センスとアンチセンスのマップをどの寥骏でどのゲノムの芹误が、券栏檬超のいつどの箕袋に券附しているか、というデ〖タベ〖スができていまして、みなさんお蝗いになることができます。センスとアンチセンスが簇わる陕丹にはインパクトのあるものがありまして、毋えばcancer(ガン)とか。 RNA络桅があります。ncRNAって部をやってるのか。泼に企脚嚎。この收の厦は办戎脚妥なんで、もう办刨おさらいしますね。 RNA络桅というのは、ノンコ〖ディングRNAの券斧でできた。じゃあノンコ〖ディングRNAってなにをやっているのと。(スライド19)毋えば、企脚嚎のノンコ〖ディングRNAが侯脱して企脚嚎のDNAのある婶尸をずばっと却き殿ることがせん逃妙で梦られていたり、ヒストンがキュッと教まってクロマチンの杜礁がおきたり。あと、decoyっていうんですけど、おとりですね、さっきmicroRNAというのの侯脱で、タ〖ゲットRNAが苟封されてぷつっと磊られるという厦がありましたけど、そのタ〖ゲットに击た、刀颁帕灰という、タンパクをコ〖ディングしていないけど紊く击たRNAがたくさんできてくることがあって、そうすると苟封するほうが、どれを苟封していいかわからないから、刀颁帕灰ばっかり苟封して、冯蔡弄にタ〖ゲットのRNAが奸られるという、そういうメカニズムがある。悸はこれは、殿钳のNatureに叫たんですけど、送の呵介の池栏だった弓撅矾が、络哄辉惟络の兜鉴やっているんだけど、揉が今いた。 それからあともう办つは、RNAがタンパクに木儡苞っ烧くことがある。毋えば、啪继傍灰に苞っ烧くなんていうのは、そのscienceの泼礁规に很ってる侠矢と、票じ规に很ってます。さっきのmicroRNAが苞き垛になってRNAiが漂く、とそういう厦をしましたけど、次隆で券附しているmiRNA122というのがあって、それがC房次标ウィルスの笼浚に涩寇だという厦も、票じ规に叫てる。つまりC房次标を迹そうと蛔ったら、そのmicroRNAの122をつぶしにいけばいいわけですよね。 だから、肌から肌へと、そういうのが叫まくっていて、ものすごくホットなわけですよ。RNAiはすごいね、なんてみんないっているけど、送らの斧つけたRNA络桅の面では、RNAiはそのほんの办婶だけだと蛔っている。戮にもいっぱいそういうメカニズムがあるはず。海までの甫垫は、セントラルドグマを面看に链坤肠の甫垫が喇惟していたわけだけど、それよりもはるかに眶の驴いRNAワ〖ルドの颁帕灰が、しかもRNAiだけじゃない、いっぱいある怠菇が、いままでのライフサイエンスの、部浇擒もでかい踏梦の挝拌を妨喇していると。しかもそれが豺汤できたら、それといままでの尸灰栏湿池と苞っ烧けなきゃいけないわけよ。それで、システム栏湿池という厦になって、劈洽陕の付傍颁帕灰があって、ここがこうなってこうなって∈スライド20徊雇∷海までは、こういう付傍となるかけらを斧つけて、それをタ〖ゲットに苟封すればいいとか泼钓をとろうとか、そういう慎にイメ〖ジしていたんだけど、悸はこれだけじゃなくて∈茶烫にncRNAが裁わる∷、悸はここにncRNAがいっぱいあるわけ。部が部を扩告しているっていうメカニズムが海までの鳞年よりもいっぱいあるから、タ〖ゲットがいっぱいあるわけね。だから、これからはncRNAを寥み哈んだシステムバイオロジ〖を雇えていかなきゃいけない。まさに踏丸の。极尸は锣幢する涟に、こういうものを豺老するその答撩を蜜いていかにゃならんと蛔ってる。 それで、じゃあ栏炭の弹富というのは、付幌の孟靛の面で傅」どうやって栏まれてきたのか。 办つには、栏湿は极尸との票じものを侯れなきゃいけない。尸灰菇陇を疯年するインフォメ〖ションがないとそれはできないんだけど、それは颁帕芭规ですよ、AGCT。でもそれだけだと、それだけだと栏湿にはなれない。それを悸狠にコピ〖するための冠燎が涩妥だから、冠燎宠拉ももってなければいけない。それにはタンパクが涩妥だけど、それはどこからできたのってはなしになるよね々だから、办つの尸灰が企つやらなきゃいけないわけですよ。DNAは冠燎宠拉积ってないですよね、菇陇惧、古いから。ただの死なんですよ。RNAはくしゃくしゃくしゃってなるから、冠燎宠拉を积てる。RNAというのは、颁帕攫鼠の拜积ができて冠燎宠拉を积てる、停办の尸灰なわけですよ。だから、RNAが、栏炭の弹富だと雇えられた。その稿、どんどん栏湿は渴步したんですね。颁帕攫鼠の拜积という罢蹋では、DNAのほうがはるかに奥年なんですよ。嫡に、剩澜のための冠燎のほうは、アミノ焕は20硷梧あるわけだから、タンパク剂に把均したほうが、はるかにバラエティがあって、渴步しやすいと。そうすると、DNAというのは嘲烧けのハ〖ドディスクみたいなもので、コンピュ〖タ〖の回吾に炳批して呵姜弄に漂くプリンタ〖みたいなのは、タンパク剂。じゃあRNAは部をやっているのかというと、ただの帕茫湿剂かと。そうではなくて、光霹栏湿であるほど笼络してくる颁帕灰を、すごく赖澄に、かつフレキシブルに扩告するシステムであると。 牢、抗俭陵が、ヒトの颁帕灰はハエの企擒か、って咐ったことがあって、澄かにタンパクをコ〖ドしている颁帕灰で咐えばそうなんです。ところが、タンパクというのは、办戎琐眉で漂く湿剂で、それが陵缄しているのは步池湿剂なんです。毋えば劈を洛颊している冠燎というのは、劈の菇陇は恃わらないんだから、ハエだろうとヒトだろうと、ものすごく奥年していて瘦赂しているはずですよね。だから、タンパクをコ〖ドしている颁帕灰は瘦赂しているんだろうけど、それを扩告しているncRNAの婶尸は、瘦赂されている涩妥はないんですよ。RNAはすべての栏炭の弹富だったわけだけど、海叉」のからだの面では保れたRNAワ〖ルドというのがまだあって、DNAとタンパクをつないでいるだけではなく、悸は链婶を扩告しているCPUそのものであると。それがだんだんわかってきたなと。それらを讳たちが斧つけてきた。 ノ〖ベル板池栏妄池巨を联ぶ把镑柴というのがあるんですけど、その把镑が叫朗する、钳に办搀のカンファレンスあるんです。どんな挝拌があるのかなぁ、と蛔って髓钳使きに乖っているんだけど、倡いたら冯菇そこからノ〖ベル巨が叫るんですよ。3钳涟にあったノ〖ベルカンファレンスは、G protein减推挛というのばっかりを礁めたやつで、そのときにしゃべったのが、江承のレセプタ〖のRichard Axelだったんだ。すごい甫垫ですわ。すごいなぁと蛔っていたら、おととしにそれがノ〖ベル巨を艰ったんですよ。その钳に、送はFunctional RNAというのをテ〖マとして叫したわけ。そしたら、痉略觉とか叫すと们るやつ办客もいない。嘶しいとか咐うて们るやついるけど、シンポジウムとかやと、でもコレばっかりはだれも们らない。だからトップだ、丸ている客たちが、垮洁がめちゃめちゃ光い。话泣粗やって、だいたいその挝拌の洛山荚弄な客が1泣のしょっぱなに厦すんやけど、办泣誊には送が厦して。2泣誊にncRNAの怠墙を拇べた客たちの厦がず〖っと。まとめ弄に厦したのはQueensland络池のJohn Mattickという客で、これも铜叹な黎栏です。话泣誊にはRNAiの厦(话泣誊の拒しい柒推は紊く使こえず)。この挝拌からは、ノ〖ベル巨办改と般うよ。セントラルドグマからはノ〖ベル巨部改もでてるわけでしょう、だったら部改もでるよ、RNAの挝拌から。 じゃぁ、剂啼は々 |
| 池栏A | いろいろ剂啼を脱罢してきたのですが、链婶こたえられてしまいました。 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
洁洒面